

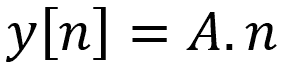
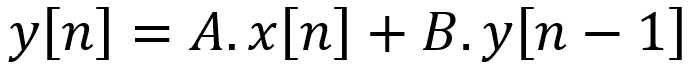

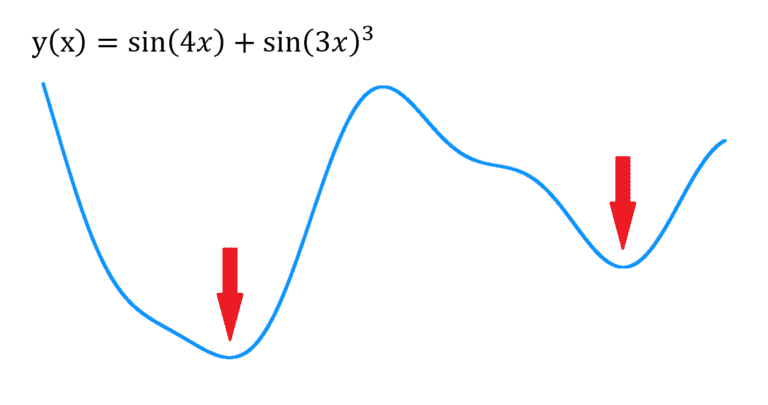
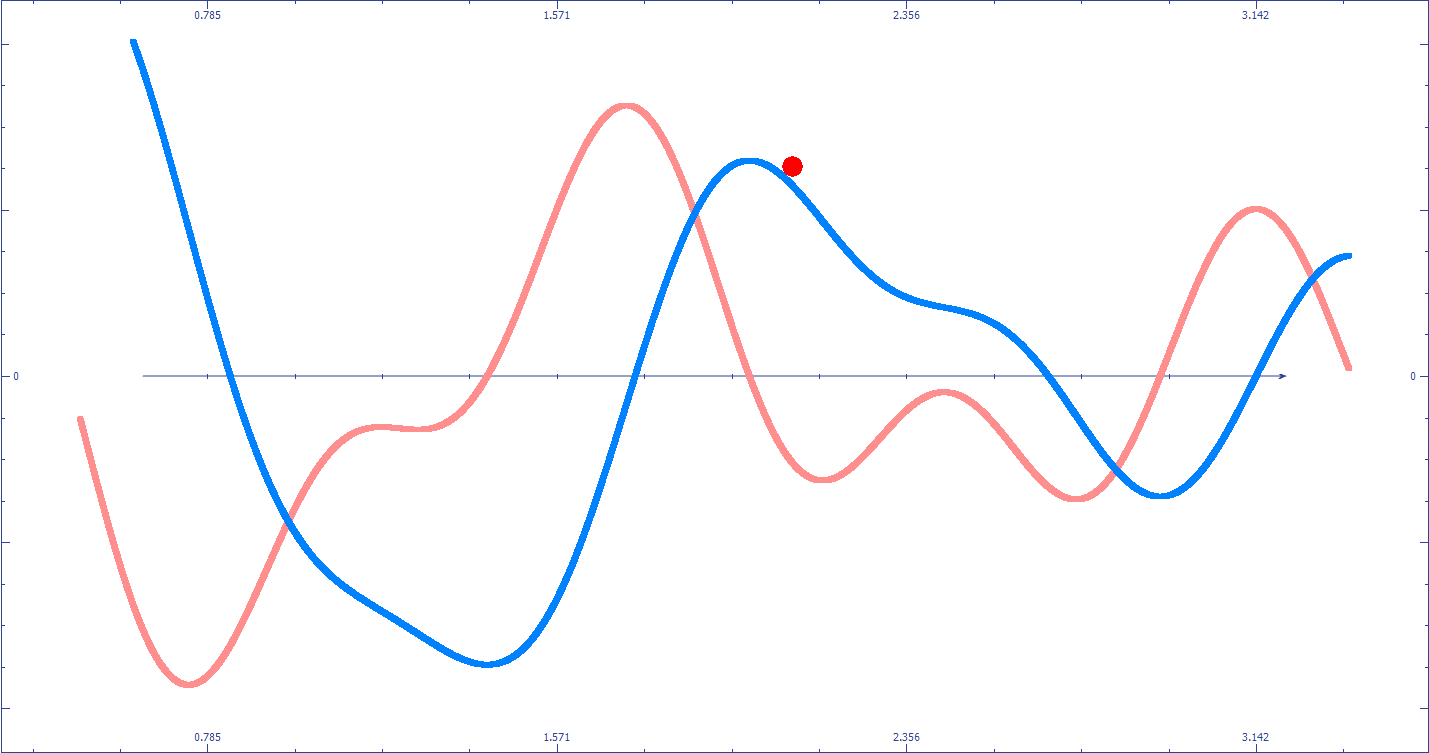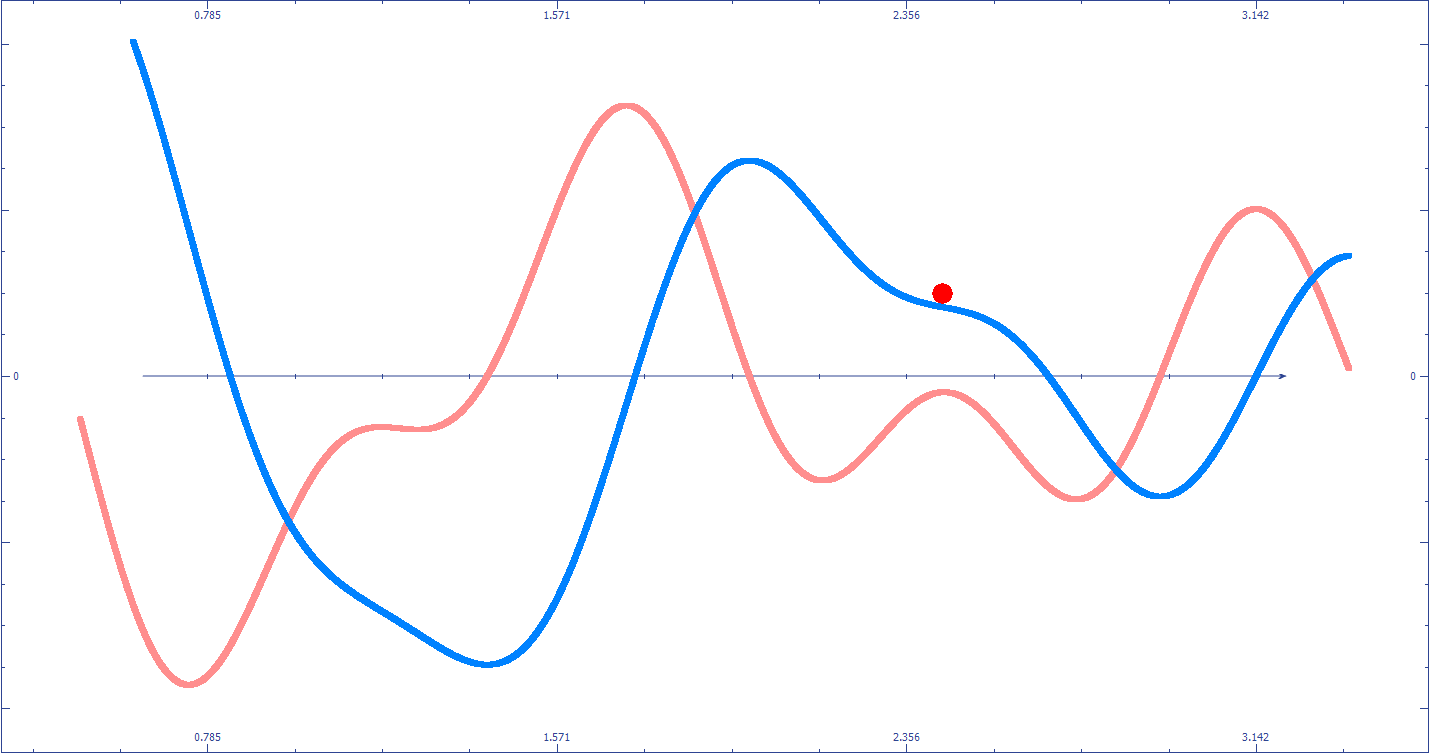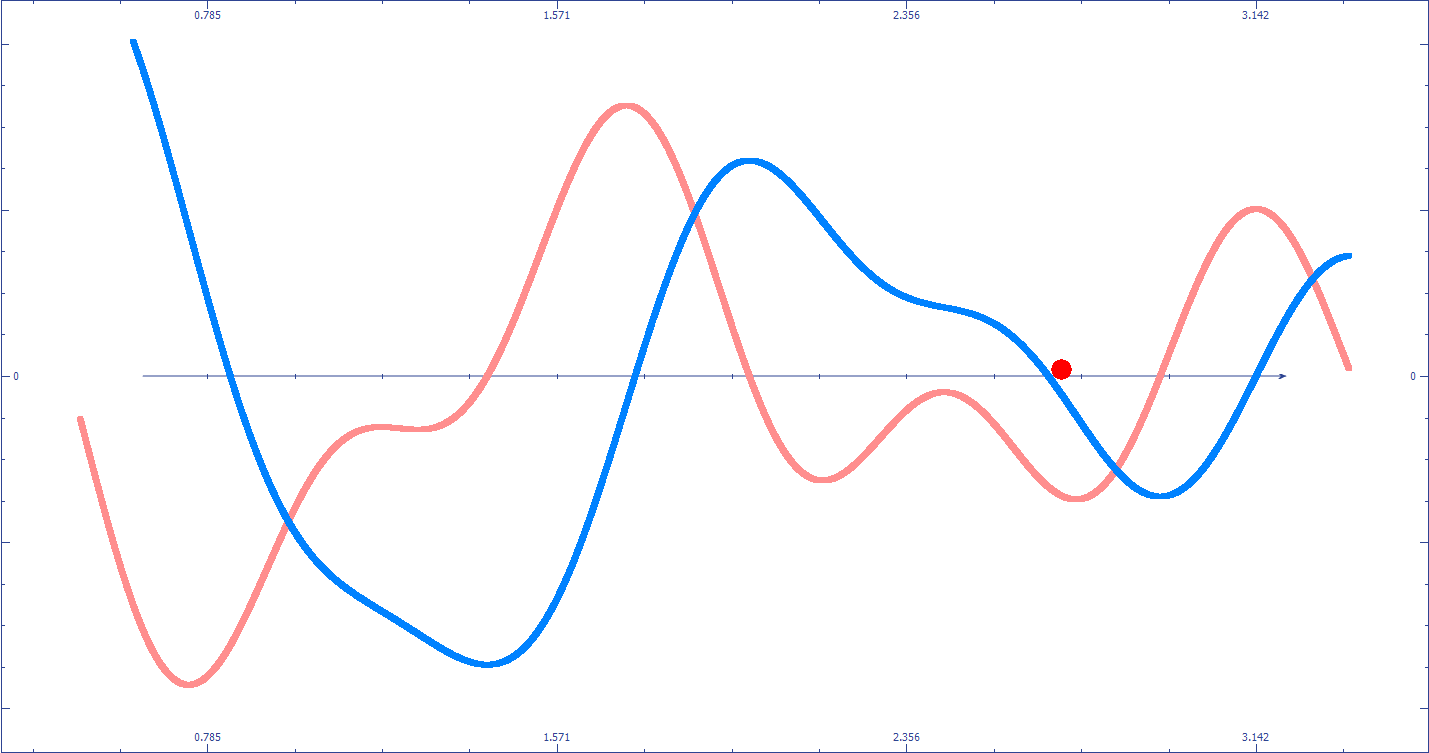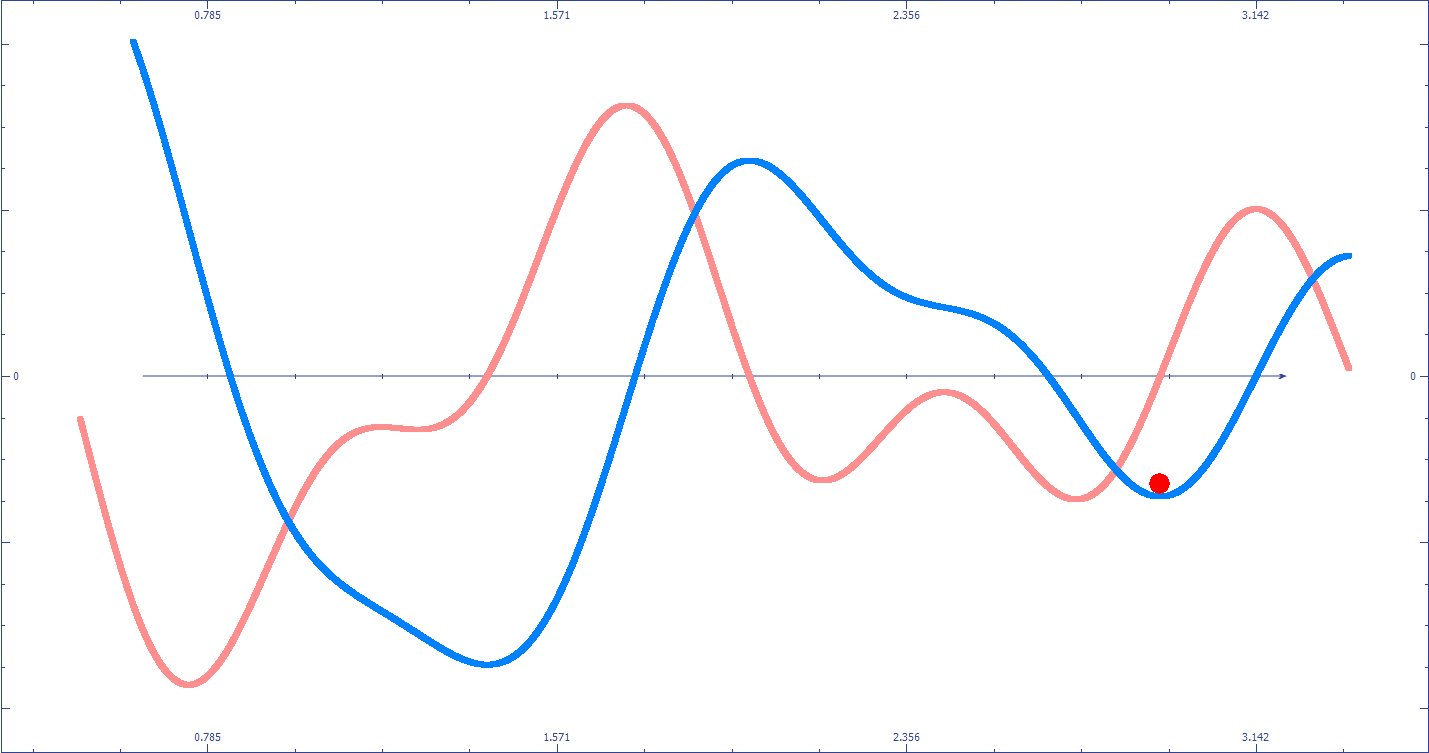
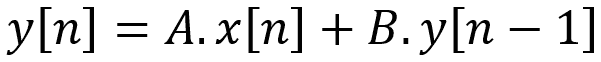
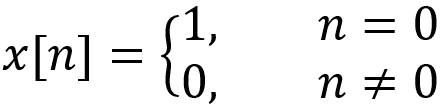
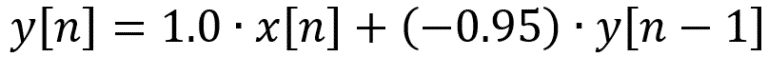
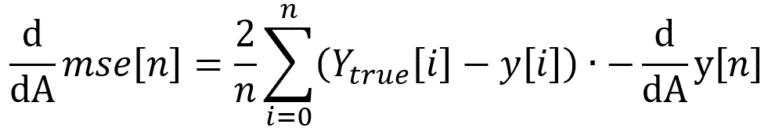
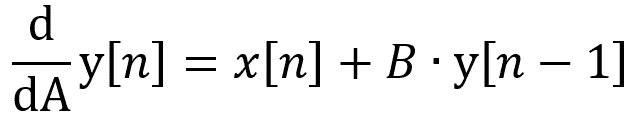
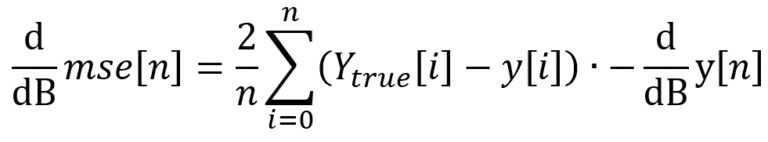
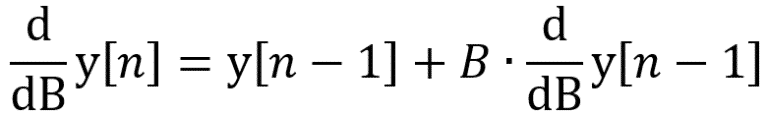
![]() La descente du gradient peut être “piégée” dans un minimum local qui ne correspond pas au minimum global (le meilleur résultat possible). Cela dépend entre autres du point de départ de vos paramètres.
La descente du gradient peut être “piégée” dans un minimum local qui ne correspond pas au minimum global (le meilleur résultat possible). Cela dépend entre autres du point de départ de vos paramètres.
![]() Votre model peut faire exploser/disparaitre le gradient, c’est à dire que la valeur du gradient devient soit trop petite soit trop grande pour être stockée sur une machine. Cela ruine l’apprentissage (essayez de mettre la constante ‘LEARNING_RATE’ à 2.0).
Votre model peut faire exploser/disparaitre le gradient, c’est à dire que la valeur du gradient devient soit trop petite soit trop grande pour être stockée sur une machine. Cela ruine l’apprentissage (essayez de mettre la constante ‘LEARNING_RATE’ à 2.0).
![]() Il faut ajuster des hyper-paramètres (learning rate, nombre d’epoch, règles d’apprentissage, etc) pour obtenir une bonne optimisation.
Il faut ajuster des hyper-paramètres (learning rate, nombre d’epoch, règles d’apprentissage, etc) pour obtenir une bonne optimisation.
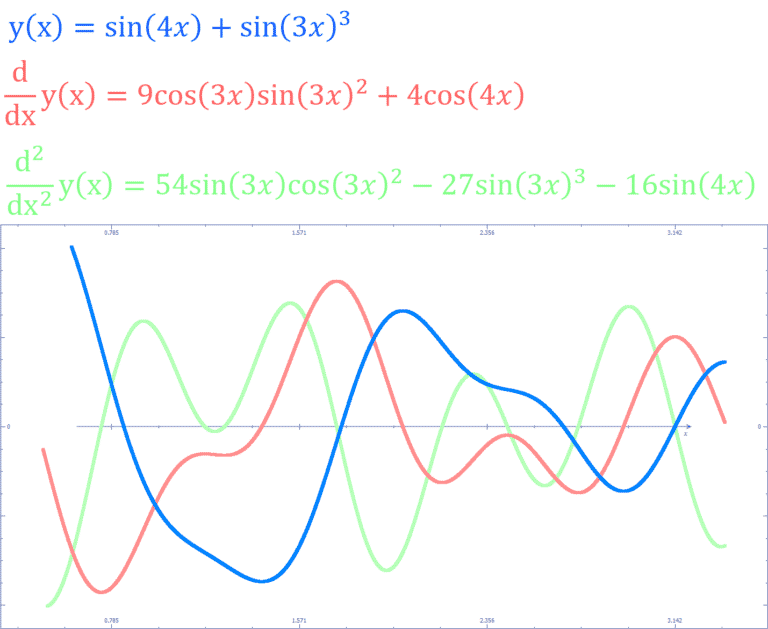
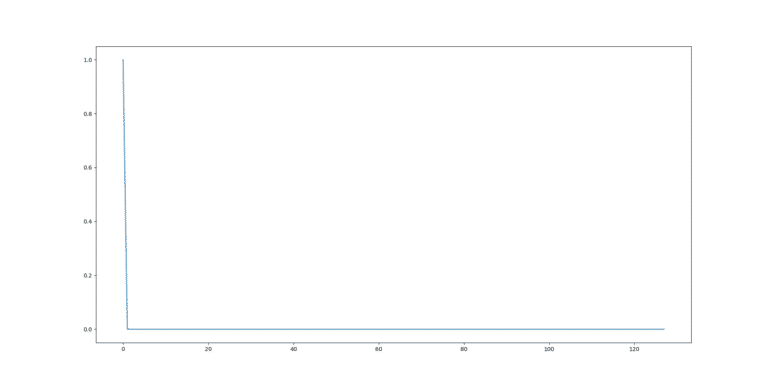
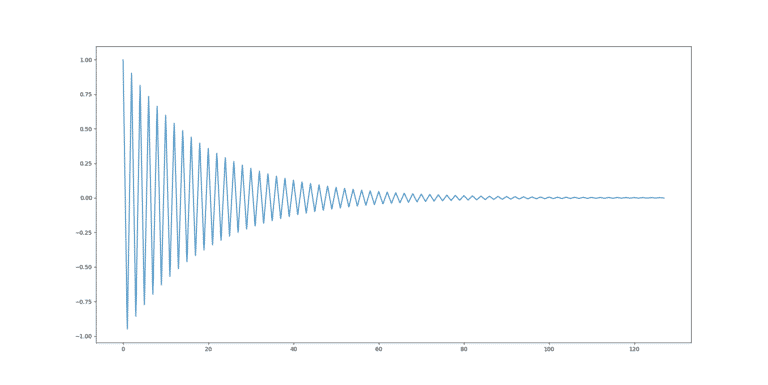
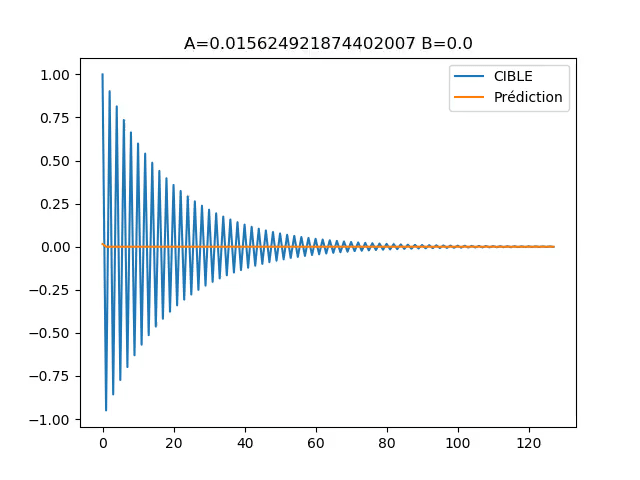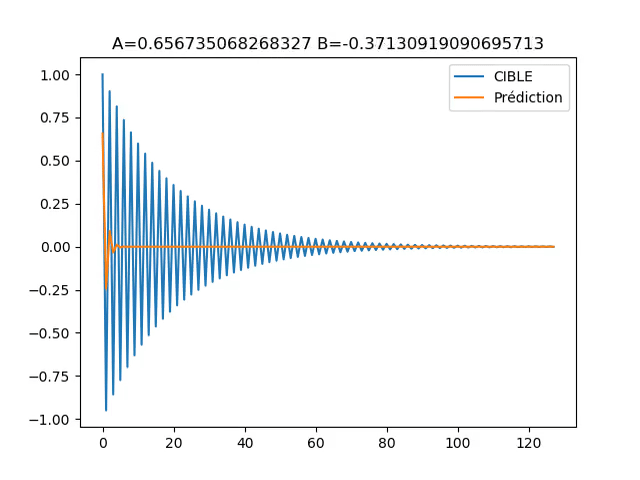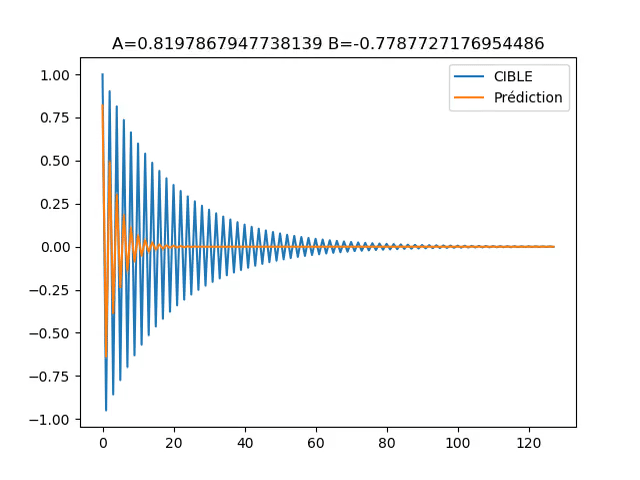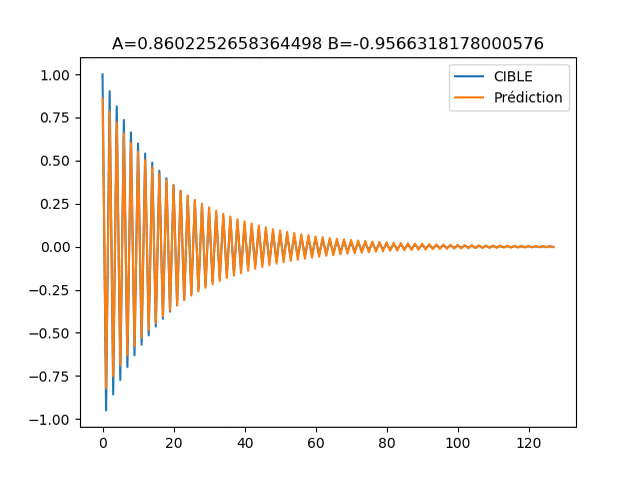
![]() L’exemple implémenté rend compte de cela, car il possède une grande zone (en ‘A’=0 et ‘B’=0) ou le gradient est faible, ce qui encourage un fort learning rate. En même temps, le gradient tend exponentiellement vers l’infini a l’approche de ‘B’=-1. Ce qui rend dangereux un learning rate trop fort.
L’exemple implémenté rend compte de cela, car il possède une grande zone (en ‘A’=0 et ‘B’=0) ou le gradient est faible, ce qui encourage un fort learning rate. En même temps, le gradient tend exponentiellement vers l’infini a l’approche de ‘B’=-1. Ce qui rend dangereux un learning rate trop fort.
![]() Le bon compromis entre nombres d’epoch / stabilitée est effectué par une règle d’apprentissage avec un learning rate décroissant au cours du temps.
Le bon compromis entre nombres d’epoch / stabilitée est effectué par une règle d’apprentissage avec un learning rate décroissant au cours du temps.
![]() L’ensemble de votre model (fonction loss compris) doit être dérivable pour chacun des paramètres. Cependant en machine learning il est courant d’avoir un model qui n’est pas 100% dérivable (activation ReLU, loss MAE, etc.). Dans ce cas il faut définir une valeur aux points non-dérivables. De même pour les opérateurs non-différentiables, par exemple l’opérateur ‘argmax’ peut être remplacé par son équivalent soft comme l’opérateur ‘softmax’ qui lui est dérivable.
L’ensemble de votre model (fonction loss compris) doit être dérivable pour chacun des paramètres. Cependant en machine learning il est courant d’avoir un model qui n’est pas 100% dérivable (activation ReLU, loss MAE, etc.). Dans ce cas il faut définir une valeur aux points non-dérivables. De même pour les opérateurs non-différentiables, par exemple l’opérateur ‘argmax’ peut être remplacé par son équivalent soft comme l’opérateur ‘softmax’ qui lui est dérivable.
Bien sûr, il existe plusieurs astuces pour limiter/contourner les défauts (model avec fonction d’activation spécifique, normalisation, fonction loss appropriée, utiliser un algorithme d’optimisation plus élaboré comme Adam, etc).