
Accélération d’un process de vision via machine learning
Accélération d’un process de vision via machine learning
Pour résoudre des problèmes, il est souvent nécessaire de modéliser leurs aspects afin de pouvoir les résoudre. La manière classique de résoudre ces problèmes consiste à en effectuer une modélisation théorique en utilisant les mathématiques par exemple.
Cependant, une telle modélisation peut parfois s’avérer gourmande en ressources machine (temps CPU, RAM, etc.) si cette modélisation devait être exécutée par une machine.
C’est pour ces raisons que nous allons explorer une autre modélisation impliquant l’utilisation du machine learning. Pour expérimenter cela, nous allons prendre pour cas d’étude un problème fictif consistant en une détection de bord sélective dans une image.
Une modélisation théorique du problème sera effectuée comme référence. Pour finir une modélisation impliquant du machine learning sera également effectuée. Le but final étant de réussir à construire un modèle de machine learning capable de faire la même chose que le modèle théorique, mais avec des performances plus attractives.
Problème : la détection de bord sélective
Le problème fictif consistera en une détection de bord sélective.
Dans notre cas, il s’agit d’effectuer une détection de bord sur une image. Cependant, cette tache est trop simplement réalisable par le biais d’une convolution.
Il est donc plus intéressant d’ajouter des contraintes afin de rendre le problème moins trivial. Par exemple en précisant le bord que l’on veut détecter suivant une condition.

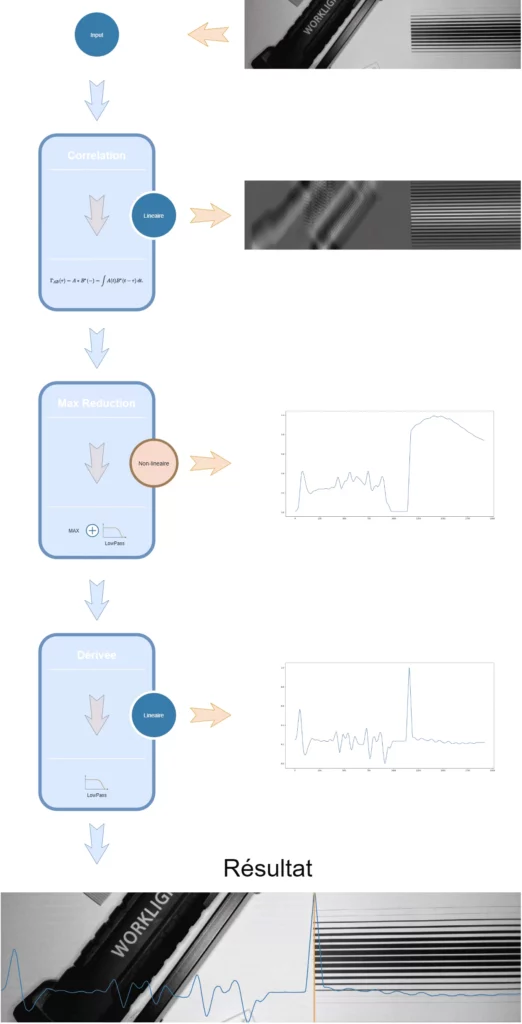
Sur l’image ci-dessus, seul le bord montré par les flèches rouge devrait être détecté. Les autres bords/contour dessinés par le motif des bandes ou les objets ne nous intéressent pas.
C’est le motif en bande qui permet de déterminer quel bord doit être trouvé (voir les flèches rouges sur l’image ci-dessus). Les autres bords ne devraient pas être détectés, car ils ne coupent pas le motif en bande.
Pour réaliser cette fonction, on peut appliquer une suite de transformation linéaire/non-linéaire sur l’image d’origine afin d’en extraire l’information qui nous intéresse. Cette phase correspond à une étude théorique du problème : une expertise doit être effectuée par un humain avec l’aide de ses connaissances (l’expérience, connaissances théoriques, etc.).
Voici un survol de l’algorithme qui effectue la détection de bords sélective sans rentrer plus dans le détail.
Première tentative : réseau de neurones convolutif (CNN)
Ce petit problème fictif, pas forcément trivial à résoudre, a permis de montrer deux aspects d’une modélisation.
La modélisation théorique a demandé des compétences théoriques en vision pour être résolue. Cependant, le temps d’exécution de cette approche n’a pas été à la hauteur des attentes souhaitées pour une application en temps réel.
Un modèle à base de machine learning a pu synthétiser/copier la tâche effectuée par l’algorithme théorique. Ce qui évite d’avoir recourt à une annotation manuelle des données pour l’apprentissage. D’autre part le modèle à base de machine learning est 4 fois plus rapide a l’exécution que le modèle théorique (>80 fois plus rapide sur mon GPU).
L’élaboration du modèle de machine learning pour ce problème a demandé un petit peu d’ingénierie dans le domaine du machine learning pour sa mise au point. On pourrait se dire que les deux problèmes demandent une expertise finalement. Ce qui est vrai, mais l’avantage du machine learning, c’est que vous n’avez pas nécessairement besoin d’être un expert en vision pour résoudre ce problème. Une annotation a la main aurait amplement fait l’affaire. Maîtriser le machine learning seul peut suffire à venir à bout des problèmes les plus difficiles.

Le réseau de neurones prend une image de 640×160 pixels en entrée, cette dernière va traverser 6 couches convolutives, pour un total de 669 paramètres entraînables. Une couche est constituée des éléments suivants :
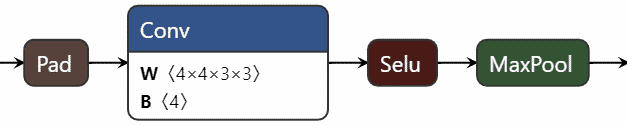
Ici le padding est géré de telles manières à conserver la proportion de l’image sur la largeur, mais pas sur la hauteur. De la même manière, le MaxPool va altérer la hauteur de l’image, mais pas la largeur. Vu que la sortie du réseau de neurones doit faire la largeur de l’image et la hauteur d’un seul pixel (une seule dimension), cette stratégie de réduction de la hauteur à travers les couches permet de faire d’une pierre deux coups. Ainsi après la première couche, la hauteur de l’image passe de 160px à 79px, la deuxième couche réduit la hauteur de 79px à 38px, etc. Jusqu’à n’avoir plus qu’un signal de 1x640px.
Toutes les fonctions d’activations sont des SeLU (une déclinaison de ReLU, utilisation classique avec les CNN) , exceptée la dernière couche qui sera une fonction d’activation Sigmoid, car la courbe que nous souhaitons générer se situe dans une plage de valeurs comprise entre 0 et 1.
Sans rentrer plus dans les détails, l’entraînement du réseau de neurones donne le résultat suivant sur des images de validations :
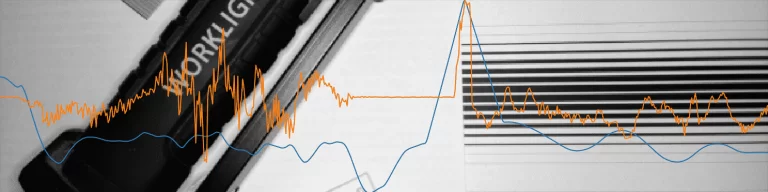
La courbe orange correspond à la prédiction faite par le réseau de neurones après entraînement. La courbe bleue correspond à la cible voulue. Cette dernière est générée par l’algorithme présenté précédemment.
Le résultat est correct, c’est-à-dire que si on regarde la position de la valeur maximale des deux courbes (en faisant l’opération argmax), on trouve à-peu-près les mêmes valeurs. De plus, le réseau de neurones s’exécute en ~20ms sur mon CPU (Intel i7-7700HQ). Pour rappel, l’ancien modèle s’exécute en ~80ms dans les mêmes conditions. Autrement dit le réseau de neurones est 4 fois plus rapide (50 FPS). L’exécution de ce même réseau sur mon GPU (GeForce GTX 1050) produit un temps d’exécution inférieur à 1 ms (> 1000 FPS) pour une taille de batch à 1.
Cependant, le signal généré par le réseau de neurones (orange) n’est pas aussi “propre” (lisse) que la courbe bleu. On remarque que la valeur moyenne des deux courbes ne sont pas les mêmes, mais cela n’a pas de grandes importances ici, car l’opérateur ArgMax ne retient que la valeur max du signal. On a tout de même plus de mal à sélectionner la valeur max avec certitude, car le signal orange comporte pas mal de bruit/valeurs parasites.
Il est très certainement possible de corriger ce problème. Pour cela, une modification de l’architecture du réseau de neurones sera nécessaire
Deuxième tentative : réseau de neurones CNN / Auto-Encodeur
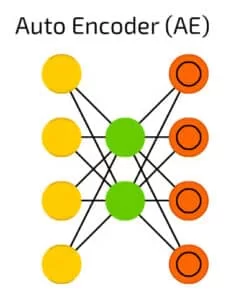
L’information arrive par les neurones de gauches (en jaune), pour sortir vers les neurones de droites (en orange).
Cependant, le signal doit passer par une zone restreinte (en vert) : l’intégralité de l’information ne pourra pas passer. En quelques sortes, cela force le réseau de neurones à faire un choix sur les données qu’il va laisser passer.
Plus concrètement, dans mon cas, un signal d’une longueur de 640 points va passer à travers l’auto-encodeur qui va le réduire en un signal de seulement 16 points avant de reconstruire un signal de 640 points à partir des 16 points précédant. Cette compression agressive devrait éliminer les valeurs parasites, car il n’y aura certainement pas la place pour tout faire passer.
La nouvelle architecture se présente comme ceci :

On note l’ajout du bloc auto-encodeur à la fin du réseau de neurones :

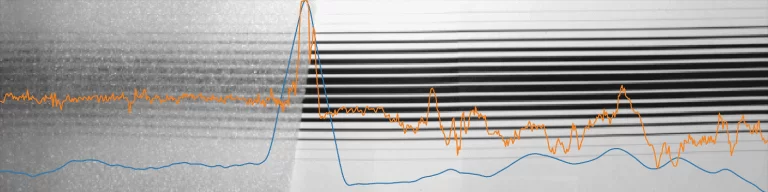
Après entraînement, les résultats sont bien meilleurs :

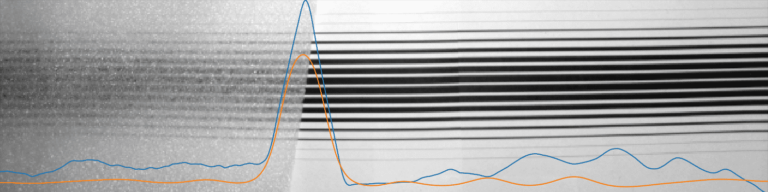
De la même manière, la courbe orange correspond à la prédiction faite par le réseau de neurones après entraînement. La courbe bleue correspond à la cible voulue.
L’ajout de ce bloc a fait passer le réseau de neurones de 669 paramètres à 21 805 (les mesures nécessaires ont été prises pour éviter l’overfitting). Il est à noter que cela n’impacte quasiment pas le temps d’exécution, car le temps d’exécution moyen est de 21ms. Seulement 1ms d’ajout par rapport à la version CNN seule